AI-based Data Retrieval System from Construction Documentation
Abstract
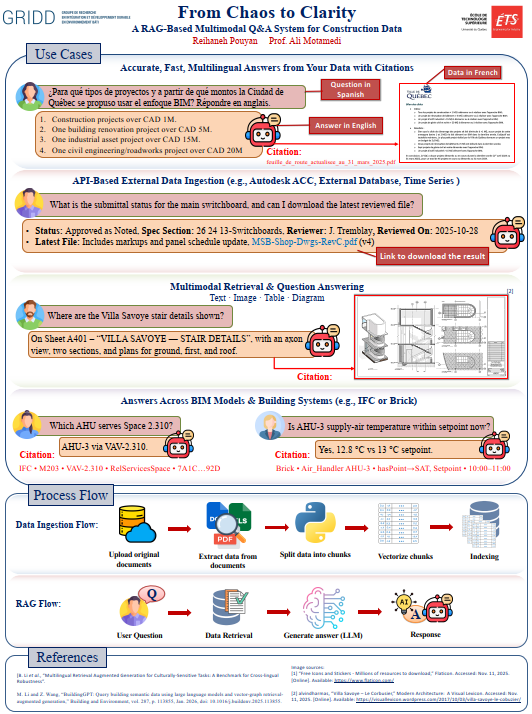
This research designs and validates an AI-based search and data retrieval system for construction documents (contracts, technical specifications, standards). Construction documentation is lengthy, heterogeneous, discipline-specific, and often multilingual, so traditional keyword search fails when users cannot guess the exact phrasing. At the same time, standalone generative AI is unreliable for professional settings due to confidentiality needs and the risk of ungrounded answers. The project develops a construction-tailored retrieval-augmented generation (RAG) pipeline: building a representative, compliant corpus; preparing documents with structure-aware chunking and metadata for filtering, provenance, and traceability; and using hybrid retrieval that combines lexical and semantic methods. Answering is strictly evidence-grounded, with mandatory citations, uncertainty detection, and abstention when evidence is insufficient. The system will be implemented under realistic deployment constraints (access control and incremental updates) and evaluated with IR metrics (Recall@k, Precision@k, MRR, nDCG), plus faithfulness, citation relevance, abstention quality, latency, and indexing efficiency in industrial case studies.
This research is expected to deliver a validated, deployable AI-based search and data retrieval system that enables natural-language querying over heterogeneous construction documents and returns evidence-grounded answers with explicit citations. The main expected results are:
1. Retrieval performance improvements: Compared to baseline keyword search, the system should demonstrate higher recall and ranking quality on representative construction queries, measured through standard information retrieval metrics (Recall@k, Precision@k, MRR, nDCG@k). Gains are expected particularly for queries where users lack exact terminology or where relevant information is distributed across long, structured documents.
2. Reliable, auditable answering: The proposed RAG pipeline should produce answers that are demonstrably faithful to retrieved evidence, with mandatory citations pointing to exact document locations (e.g., section/clause/table references). Answer quality will be assessed via accuracy, faithfulness, and citation relevance; the system should minimize unsupported claims by enforcing strict grounding.
3. Uncertainty and abstention behavior: The system should reduce harmful or misleading outputs by detecting insufficient evidence and abstaining or requesting clarification. Performance will be quantified through abstention precision/recall and expert review of borderline cases, supporting safer professional usage.
4. Operational readiness under real constraints: The implementation is expected to include confidentiality-aware ingestion, access control mechanisms, and automated incremental updates to support evolving project documentation. Operational results will include acceptable latency for interactive use, efficient indexing and update times, and robust logging for traceability and governance.
5. Industrial validation: Through case studies with corporate partners, the system is expected to demonstrate measurable productivity gains (reduced search time, fewer missed requirements, improved compliance checks) and increased user trust due to transparent citations and consistent behavior.
Overall, the project aims to show that construction-specific RAG can outperform traditional search while remaining safer and more trustworthy than unconstrained generative AI.
Contributions du projet
Academically, this work will define and test a structure-aware retrieval pipeline for construction documents, comparing chunking, embeddings, and hybrid retrieval choices, and measuring their impact on retrieval quality, citation correctness, and abstention reliability.
Industrially, it will deliver a practical, secure search-and-answer system that fits real project constraints: confidential data handling, role-based access control, and automatic incremental updates when new document versions arrive. Users will be able to ask questions in natural language and receive short, evidence-based answers with clear citations to the exact section/clause (and table rows when relevant). When evidence is missing or ambiguous, the system will refuse or ask for clarification instead of guessing. Validation with corporate case studies is expected to show less time spent searching, fewer missed requirements, stronger compliance checks, and improved trust because results are auditable and repeatable.
{kind=link}
